my_text1 = '나는 파이썬을 좋아해!'
my_text2 = "파이썬 사용하기 쉽고 강력한 기능을 제공해."
my_text3 = """The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
......"""7 문자열(String) 시퀀스
파이썬 문자열(String)에는 3가지 내장 데이터 타입이 있는데, 처음 파이썬을 배울 때 bytes, bytearray를 다뤄야할 일은 거의 없기 때문에 여기서는 str 데이터 타입에 대해서만 설명한다.
str: 텍스트 데이터, immutablebytes: 바이너리 데이터, immutablebytearray: 바이너리 데이터, mutable
str은 character들로 구성된 immutable sequence이다. 1
7.1 문자열 만들기
문자열 리터럴은 작은따옴표(') 또는 큰따옴표(") 또는 3개의 따옴표(""" 또는 ''')로 텍스트를 둘러싸서 만든다.
작은따옴표를 사용하는 것과 큰따옴표를 사용하는 것의 차이는 없다. 하지만 작은따옴표로 만든 문자열 안에 작은따옴표를 쓸 수 없고 큰따옴표 안에 큰따옴표를 쓸 수 없다. 따라서 문자열 안에 따옴표가 필요한 경우는 다른 방법을 취한다.
my_text1 = "그는 '파이썬'을 좋아한다고 한다."
my_text2 = '그 친구는 "파이썬을 좋아한다."고 말했다.'다음과 같이 여러 행으로 출력되는 텍스트를 만들 때 작은따옴표, 큰따옴표를 사용한 문자열을 만들기 쉽지 않다.
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.작은따옴표, 큰따옴표를 사용한 문자열로 이렇게 출력하게 만들려면 다음과 같이 해야할 것이다.
my_text = "\
The Zen of Python, by Tim Peters\n\
\n\
Beautiful is better than ugly. \n\
Explicit is better than implicit.\
"
print(my_text)The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.이처럼 물리적으로 여러 줄(행)으로 출력되는 텍스트 데이터를 만들려면 줄바꿈이 필요한 곳에 역슬래쉬(\)을 넣어 주어야 한다. 그렇지만 실제 출력을 해도 줄이 바뀌지 않는다. 실제 줄바꿈을 하려면 줄바꿈 문자인 \n을 써주어야 한다.
3개 따옴표를 사용하는 경우는 이런 것이 필요없이 파이썬이 자동으로 알아서 처리해 준다. 함수와 클래스의 docstring은 여러 행으로 작성되는 경우가 많기 때문에 이런 경우 3개의 따옴표를 주로 사용한다(뒤에서 설명된다).
my_text = """
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
"""
print(my_text)
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
7.2 파이썬 Strting은 Sequence의 일종이다.
파이썬 String은 sequence의 일종이기 때문에 6장 시퀀스(Sequence)에서 설명한 sequence의 특징과 기능을 모두 가진다.
문자열을 보는 관점
텍스트는 인간이 읽을 수 있기 때문에, 우리가 문자열을 볼 때 다른 데이터와는 다르게 약간의 편견 내지는 선입관을 가질 수 있다. 문자열은 텍스트 한 글자 한 글자들이 연달아 이어진 sequence라고 의식적으로 기계적인 관점을 가질 필요가 있다. 이런 관점은 나중에 정규 표현식(regular expression)을 이해할 때도 도움이 된다.
my_text = "파이썬 사용하기 쉽고 강력한 기능을 제공해."# 서브 문자열이 포함.
"파이썬" in my_textTrue# 아이템의 개수
len(my_text)24# list comprehension
[c for c in my_text]['파',
'이',
'썬',
' ',
'사',
'용',
'하',
'기',
' ',
'쉽',
'고',
' ',
'강',
'력',
'한',
' ',
'기',
'능',
'을',
' ',
'제',
'공',
'해',
'.']# 리스트로 만들기
print(list(my_text))['파', '이', '썬', ' ', '사', '용', '하', '기', ' ', '쉽', '고', ' ', '강', '력', '한', ' ', '기', '능', '을', ' ', '제', '공', '해', '.']# unpackging
c1, c2, c3, *_ = my_text
print(c1, c2, c3, sep=", ")파, 이, 썬# 정렬
sorted(my_text)[' ',
' ',
' ',
' ',
' ',
'.',
'강',
'고',
'공',
'기',
'기',
'능',
'력',
'사',
'쉽',
'썬',
'용',
'을',
'이',
'제',
'파',
'하',
'한',
'해']# 슬라이싱
my_text[:5]'파이썬 사'# concatenation
"파이썬 사용하기 쉽고 " + "강력한 기능을 제공해."'파이썬 사용하기 쉽고 강력한 기능을 제공해.'# repetition
"파이썬" * 3'파이썬파이썬파이썬'7.3 이스케이핑(Escaping)
위 예에서 문자열 안에서 사용된 \ 또는 \n(줄바꿈)은 특수한 목적으로 사용되는 일반 텍스트와 다른 것으로 이런 종류를 이스케이프 시퀀스(escape sequence)라고 한다. 다음은 \t은 탭을 표시하는 이스케이프 시퀀스이다. 이처럼 문자열 안에서 \으로 시작되는 것이 이스케이프 시퀀스가 이외에도 여럿 있다.
my_text = "좋아하는 언어: \t파이썬"
print(my_text)좋아하는 언어: 파이썬만약 문자열 안에서 역슬래쉬를 포함시켜야 하는 경우에는 역슬래쉬를 다시 이스케이핑해야 해서, 역슬래쉬 2개를 사용하여 표현한다.
my_text = "좋아하는 언어 \\ 보통인 언어"
print(my_text)좋아하는 언어 \ 보통인 언어7.4 Raw string literal
문자열의 한 종류로 따옴표 바로 앞에 r을 붙여서, r"..."과 같은 문법으로 만드는 문자열을 raw string literal이라고 한다. Raw string literal에서는 이스케이프 시퀀스가 다 무시된다. 따라서 문자열에 백슬래쉬를 자주 사용해야 하는 경우에 이런 문자열을 주로 쓴다.
my_text1 = "좋아하는 언어 \\ 보통인 언어"
print(my_text1)
my_text2 = r"좋아하는 언어 \\ 보통인 언어"
print(my_text2)좋아하는 언어 \ 보통인 언어
좋아하는 언어 \\ 보통인 언어파이썬 코딩 때 이런 raw string literal을 사용하는 가장 흔한 경우는 정규표현식(regular expression)으로 텍스트에 대한 패텬을 만들 때이다. 다음은 전화번호를 추출하기 위한 것은 텍스트 패턴을 만들 때 숫자(digit)을 의미하는 문법이 \d이기 때문에, raw string literal을 사용하지 않으면 앞에 역슬래쉬를 이스케이핑을 해야 하니까 패턴을 만드는 문자열의 가독성을 떨어뜨릴 수 있다.
import re
phone = re.compile(r'\d{3}-\d{4}-\d{4}')
text = "내 전화번호는 010-1245-5678이다."
mo = phone.search(text)
mo.group()'010-1245-5678'7.5 함수, 클래스의 docstring
파이썬 함수나 클래스 정의해서 그 body의 첫 번째 문장에 문자열을 놓으면, 이것은 그 함수나 클래스의 docstring이 되고, help() 함수에 해당 객체를 놓으면 이 문자열이 표시된다.
def my_f(n):
"""add plus one to given argument"""
return n + 1
help(my_f)Help on function my_f in module __main__:
my_f(n)
add plus one to given argument
class Student:
"""the name and department of student"""
def __intit__(self, name, depart):
self.name = name
self.depart = depart
help(Student)Help on class Student in module __main__:
class Student(builtins.object)
| the name and department of student
|
| Methods defined here:
|
| __intit__(self, name, depart)
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables
|
| __weakref__
| list of weak references to the object
주의할 점은 body의 첫 번째 문장이라야 되고, 보통은 경우는 3개의 따옴표를 사용한다는 점이다.
7.6 문자열 str의 메서드
문자열을 쪼개는 역할을 하는 메서드가 str.split()이다.
- 공백 문자가 쪼개는 기준이 된다.
- 결과는 list로 반환한다.
text = "파이썬 사용하기 쉽고 강력한 기능을 제공해."
text.split()['파이썬', '사용하기', '쉽고', '강력한', '기능을', '제공해.']반대로 iterables에 항목들을 묶어서 하나의 문자열을 만드는 메서드가 str.join()인데, 다음과 같이 사용한다.
str부분에는 합칠 때 중간에 둘 문자열을 지정한다.join()안에는 하나의 iterable을 준다.
words = ('파이썬', '사용하기', '쉽고', '강력한', '기능을', '제공해.')
":".join(words)'파이썬:사용하기:쉽고:강력한:기능을:제공해.'공백 문자들을 제거하는 매서드가 str.strip()(양쪽), str.ltrip()(왼쪽), str.rtrip()(오른쪽) 메서드가 있다.
text = " 파이썬 "
print(text.strip())
print(text.lstrip())
print(text.rstrip())파이썬
파이썬
파이썬한글을 사용하는 경우에는 필요하지 않겠지만, 대문자로 만드는 str.upper(), 소문자로 만드는 str.lower() 등과 같은 메서드가 있다.
문자열에 숫자가 들어가 있는 경우(digits) 이 값을 숫자로 변환시킬 수 있다.
print(float("123.456"), int("123"))
print(int("123", 16)) # "123"이 16진수라는 것을 표시, 이것을 10진수 정수로 123.456 123
2917.7 문자열 포맷팅: f-string, str.format(), format()
문자열 포맷팅은 문자열에 파이썬 데이터 값을 내삽(interpolation)하는 방법이다. 핵심은 그 값을 사용자가 원하는 형태의 출력을 얻을 수 있게 조절하는 방법을 아는 것이 핵심이다.
f-string: 문자열 바로 앞에f를 붙여서 만들고, 문자열 안에{}로 생성되는 대체 필드(replacement field) 포함한다. 이 방법은{}에 직접 파이썬 표현식을 넣는다.str.format(): 대체 필드를 포함하는 문자열에 대하여format()메서드를 실행하여 만든다. 이 경우는format()의 인자들을 통해 안의 대체 필드에 값을 전달한다.format(obj, format_spec): 어떤 객체에 대상으로 주어진format_spec에 따라 출력하게 한다.
import math
f'원주율 파이의 값은 {math.pi}이다.''원주율 파이의 값은 3.141592653589793이다.'import math
'원주율 파이의 값은 {0}이다.'.format(math.pi)'원주율 파이의 값은 3.141592653589793이다.'import math
def radius_area(r):
return r, math.pi * r ** 2
'반지름이 {0}인 원의 넓이는 {1}이다.'.format(*radius_area(5))'반지름이 5인 원의 넓이는 78.53981633974483이다.'정수 42를 가지고 format() 함수의 용도를 보자.
# 너비를 4로
print(format(42, '4'))
# 이진수로 표현
print(format(42, 'b'))
# 16진수로 표현
print(format(42, 'X')) 42
101010
2A뒤에서 format(), f-string, str.format()이 모두 __format__()에 의해서 실행되는 것으로 서로 밀접한 관계가 있다는 것을 배우게 될 것이다.
7.7.1 f-string과 str.format() 사용법
f-string에서는 대체 필드에 파이썬 표현식을 바로 넣는다.
name = "홍길동"
print(f"나의 이름은 {name}입니다.")나의 이름은 홍길동입니다.import math
radius = 5
print(f"""
반지름 {radius}인
원의 면적은 {math.pi * (radius **2)}이다.
""")
반지름 5인
원의 면적은 78.53981633974483이다.
str.format()인 경우에는 인자의 값이 대체 필드로 값이 전달된다.
- 위치(positional)에 따른 방법: 인자를
0번에서 시작하고, 대체 필드에 그 번호를 지정한다. 잉여 인자는 무시된다.
"값은 {1}, {2}, {3}, {0}이다.".format(*range(5))'값은 1, 2, 3, 0이다.'- 키워드에 따른 방법: 그 인자의 이름을 지정한다. 잉여 인자는 무시된다.
"값은 {first}, {second}, {third}".format(first=5, second=3, third=7, fourth=10)'값은 5, 3, 7'7.7.2 대체 필드와 Format Specification Mini-Language
앞에서 원주율을 출력해 보았는데, 소수점 아래 수 등을 원하는 형태로 조절할 필요가 있을 수 있다. 원하는 결과를 얻기 위해서 {}(대체 필드) 안을 코딩하는 방법에 대해서 알아보자. 이 부분은 3개의 파트로 구성된다.
- value-part
- conversion-part
- format-spec
작성 문법은 다음과 같다.
{value-part[!conversion-part][:format-spec]}앞에서 {math.pi}처럼 value-part는 f-string인 방법에서는 반드시 필요하고, str.format() 방법에서는 인자의 순서에 따라 차례대로 값이 채워지는 경우는 안 써도 된다. !로 시작되는 conversion-part와 :으로 시작되는 format-spec은 옵션이다.
# value-part와 format-spec
import math
print(f'원주율 파이의 값은 {math.pi:.2f}이다.')원주율 파이의 값은 3.14이다.참고로 이 경우는 math.pi의 값을 소수점 2자리수의 부동소수점수로 표시하라는 뜻이다.
# value-part와 format-spec
import math
def radius_area(r):
return r, math.pi * r ** 2
print('반지름이 {0}인 원의 넓이는 {1:.2f}이다.'.format(*radius_area(5)))반지름이 5인 원의 넓이는 78.54이다.conversion-part은 !r은 repr() 함수, !s는 str() 함수, !a는 ascii() 함수로 렌더링되게 한다. 이 부분은 뒤에서 다시 설명한다.
formar-spec은 다음과 같이 사용된다. 이것을 파이썬에는 Format Specification Mini-Language라고 부른다.
format_spec ::= [[fill]align][sign]["z"]["#"]["0"][width]
[grouping_option]["." precision][type]
fill ::= <any character>
align ::= "<" | ">" | "=" | "^"
sign ::= "+" | "-" | " "
width ::= digit+
grouping_option ::= "_" | ","
precision ::= digit+
type ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" |
"G" | "n" | "o" | "s" | "x" | "X" | "%"format_spec 이 부분은 다음과 같다.
[[fill]align][sign]["z"]["#"]["0"][width][grouping_option]["." precision][type]이 순서대로 값을 지정하는데 그 의미는 다음과 같다. 자세한 내용은 파이썬 매뉴얼을 참고한다.
fill: 공백을 채울 값align: 좌, 우, 중앙 정렬width: 전체 문자열의 폭grouping_option: 숫자 1000 단위를 구분하는 기호.precision: 소숫점 이하의 수(정밀도)type: 텍스트, 숫자(정수, 부동소수점 수, 과학 표기, 16진수, 퍼센티지 등)
# '#'으로 채움, 중앙 정렬(^), 전체 20칸, 소수점 3자리, 부동소수점
# > 오른쪽, < 왼쪽, ^ 중앙 정렬
# type f는 부동소수점수
import math
f"파이: {math.pi:#^20.3f}"'파이: #######3.142########'# type e는 과학적 표기를 의미
import math
f"파이: {math.pi:20.7e}"'파이: 3.1415927e+00'# grouping_option ,으로 구분
cost = 10000000
f"비용은 {cost:,.0f}원이다."'비용은 10,000,000원이다.'7.8 파이썬이 문자열을 다루는 방식
노트
아래는 참고용으로 파이썬이 문자열을 다루는 방식에 대한 설명인데, 핵심을 요약하면 다음과 같다.
파이썬에서는 UTF-8 인코딩을 사용하여 문자열을 표현한다. 파이썬을 처음 배우는 때, 특히 한글을 표현할 때 영문자와는 다를 것이라고 생각할 수 있지만, 파이썬은 문자열을 다루는 방식이 영문자와 한글 모두 동일하다. 이것은 파이썬이 문자열을 다루는 방식이 Unicode를 기반으로 하기 때문이다.
유니코드 시스템에서는 한글 자음과 모음으로 이루지는 음절 하나하나에 대해 하나의 코드 포인트를 부여한다. “가”의 코드 포인트가 있고, “강”의 코드 포인트가 있고, “갂”의 코드 포인트가 따로 있다. 따라서 이것들을 동등한 하나의 문자인 것이다.
len("가"), len("강"), len("갂")(1, 1, 1)컴퓨터에서는 모든 것을 숫자로 표현한다. 문자(character)도 마찬가지이다. 특정 문자를 컴퓨터에서 표현하기 위해서는 그 문자를 숫자로 바꾸어야 한다. 이 숫자를 문자 코드(character code)라고 한다.
예를 들어서 “가”라는 문자를 컴퓨터에서 표현하기 위해서는 “가”라는 문자를 숫자로 바꾸어야 한다. 이 숫자가 바로 문자 코드이다. “가”라는 문자를 컴퓨터에서 표현하는 방법은 여러 가지가 있다. 가장 일반적으로 사용되는 방법은 유니코드(Unicode)이다.
유니코드(Unicode)는 전 세계의 모든 문자를 다루도록 설계된 표준의 하나이다. Unicode는 0에서 1백만 이상으로 이어지는 각 번호에 세상에 존재하는 character들을 1:1로 배정한 것이다. 그 번호를 Unicode code point라고 한다. Unicode code point는 유니코드 시스템에서는 U+ 접두사에 16진수들을 붙여서 표현한다. 16진수 4자리에서 6자리까지 이용하는데 실제로 U+0000에서 U+10FFFF까지 사용한다.
16진수 10FFFF를 10진수로 바꾸어 보면 다음과 같다.
1 * (16**5) + 0 * (16**4) + 15 * (16**3) + 15 * (16**2) + 15*(16) + 151114111따라서 0 ~ 1,114,111 번호가 있고 문자 하나는 이 번호 가운데 하나와 매칭된다. “가”는 U+AC00에 할당되어 있다. 문자열 안에서 \u를 사용하면 이 값에 접근할 수 있다.
print("\uAC00")가U+AC00을 “가”라는 문자의 유니코드 코드 포인트라고 말한다.
파이썬 내장 함수 ord()는 Unicode code point 값(10진수)을 반환한다. 이 함수를 사용하여 다음 character들의 Unicode code point를 살펴보자.
[ord(c) for c in "AB가각나"][65, 66, 44032, 44033, 45208]Unicode가 16진수를 사용하고 있으므로, hex() 함수를 사용하여 16진수로 표현해 보면 다음과 같다.
[hex(ord(c)) for c in "AB가각나"]['0x41', '0x42', '0xac00', '0xac01', '0xb098']실제 Uncode 코드 데이터베이스를 보면 “가”, “각”이 그림 7.1과 같이 등재되어 있다. 위 결과를 표와 맞춰 확인해 보자.
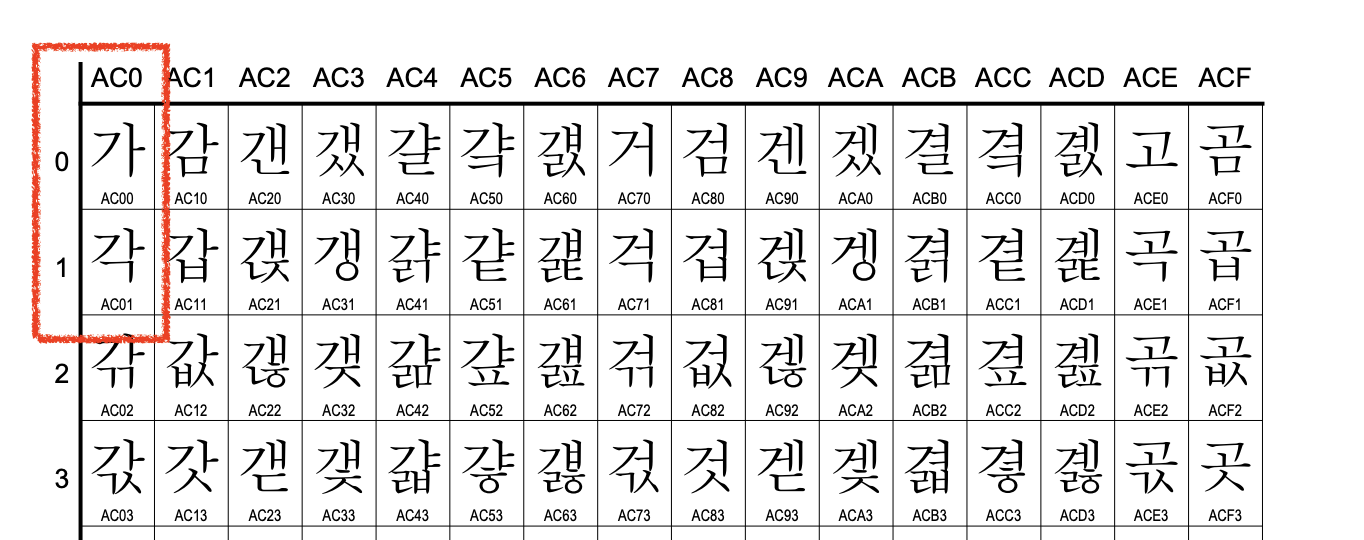
위 그림에서 하나 알아둘 사항은, 한글의 경우 초성, 중성, 종성의 조합을 통해 하나의 음절이 만들어질 수 있는데(현대 한글 초성, 중성, 종성의 조합으로 11,172자를 만들 수 있다), 이렇게 만들어지는 하나의 음절에 대응하는 하나의 코드가 부여되어 있다는 점이다. 예를 들어서 “가”는 U+AC00이고, “각”은 U+AC01이다.
chr() 함수는 Unicode code point 값(숫자)을 받아서 해당하는 문자를 반환한다. 안의 인자는 10진수를 사용할 수도 있고, 16진수를 사용할 수도 있다.
[chr(n) for n in [65, 66, 44032, 44033, 45208]]['A', 'B', '가', '각', '나'][chr(h) for h in [0x41, 0x42, 0xac00, 0xac01, 0xb098]]['A', 'B', '가', '각', '나']유니코드 시스템은 세상의 존재하는 거의 모든 문자에 대해서 숫자 코드를 부여한 것이다. 당연히 한글도 여기에 포함된다. 한글의 경우 역사적으로 여러 가지 과정을 거쳐 Unicode 2.0부터 완성형 현대 한글 음절에 대한 코드를 할당받았으며, 또한 이것이 우리나라의 한글 코드의 공식 표준이 되었다.
파이썬 3의 str 데이터 타입은 Unicode character들로 구성된 시퀀스이며, 한글 음절 하나하나가 하나의 Unicode code point를 가지고 있어서, 영문 문자열과 다름없이 사용 가능하다. 심지어 함수나 변수 이름도 한글로 사용할 수 있다.
7.9 문자를 이진 데이터로, 이진 데이터를 문자로
앞에서 유니코드를 설명했는데, 유니코드 말고도 다양한 문자 코드 시스템이 있다. 예를 들어서 ASCII, ISO-8859-1, EUC-KR 등이 있다. 이 문자 코드 시스템은 문자(character)와 숫자(code point) 사이의 매핑(mapping)을 정의한다. 이런 문자 코드를 컴퓨터가 이해할 수 있는 이진 값으로 바꾸는 과정을 인코딩(encoding)이라고 한다. 반대로 이진 값을 문자로 바꾸는 과정을 디코딩(decoding)이라고 한다.
(요즘에 사용되는) 파이썬 3.0에서 작은따옴표, 큰따옴표, 트리플따옴표 등으로 만드는 일반적인 텍스트 문자열은 Unicode UTF-8 인코딩 방식으로 만들어지고 저장된다. 파이썬 소스 파일도 UTF-8 인코딩을 방식을 사용한다.
- Python 3.0의 default encoding은 UTF-8이다.
이런 이진 값으로 구성되는 파이썬 객체가 bytes(immutable), bytearray(mutable) 시퀀스이다.
문자열을 encoding 하는 함수는 str.encode()이고 여기에 코덱은 인자를 지정해 준다. 다음 예를 보자. 이 함수는 그 결과를 bytes 객체로 반환한다.
my_text = "안녕하세요, 파이썬!"
my_text.encode('utf-8')b'\xec\x95\x88\xeb\x85\x95\xed\x95\x98\xec\x84\xb8\xec\x9a\x94, \xed\x8c\x8c\xec\x9d\xb4\xec\x8d\xac!'이 bytes를 원래의 텍스트로 변화할 때는 bytes.decode() 함수를 사용한다.
my_text.encode('utf-8').decode('utf-8')'안녕하세요, 파이썬!'